How We Optimise for Google Gemini
So before I delve into this - I have to make it clear, I, nor anybody else truly knows how Gemini works, we have some idea, but Google's constantly changing Gemini, and, fundamentally, a lot of traditional SEO is going to apply to Gemini's selection criteria during response generation.
SO, for that matter I do NOT profess to be an expert here, what I do claim is backed by sources, I've read up from Google Search Central, Firebase and Vertex AI to understand grounding with Google - I've also performed a lot of my own tests so I have my own theories.
Right let's get stuck in.
Gemini is not a separate search engine you can game with a separate set of SEO tricks or hacks. It reads off Google's live search index, and Google's in-Search AI features, AI Overviews and AI Mode are powered by the same Googlebot crawl that has decided organic rankings for more than two decades.
Roughly half of all AI Mode citations are drawn from pages already ranking in the top ten. So the first thing we tell clients is uncomfortable but true, if your pages don't rank, no "AI optimisation" tactic will save them. Gemini visibility is not a thing you bolt on, it is what strong, well-structured organic search performance looks like when an Gemini is doing the grounding.
What I do suggest for anyone learning about LLMS should do is learn about the specific components of how they work - the better understand how they work, the more you can tailor your forward knowledge & testing to find what works for you!
Here's a useful starting point - Google's own grounding with google search article is a good read. They've made it easy to understand -
What changes is how the grounding, evaluation & RAG happens and that is where I see most misinformation being spread - mostly GEO Experts shouting "GEO, GEO, GEO" from the rooftops, most of which probably have no idea how Gemini works nor how it's integrated into search.
Before we even think about optimising for Google's AI ecosystem, we think with common sense applied (along with research that gives us a fundamental idea of how gemini works, or, at least how we think it works).
So - applying a concept of "how it works" to a forward strategy helps us to make better decisions when helping clients with being cited in Gemini or AI Overviews - some of the key rationale we apply is the logic from PROMPT to OUTPUT.
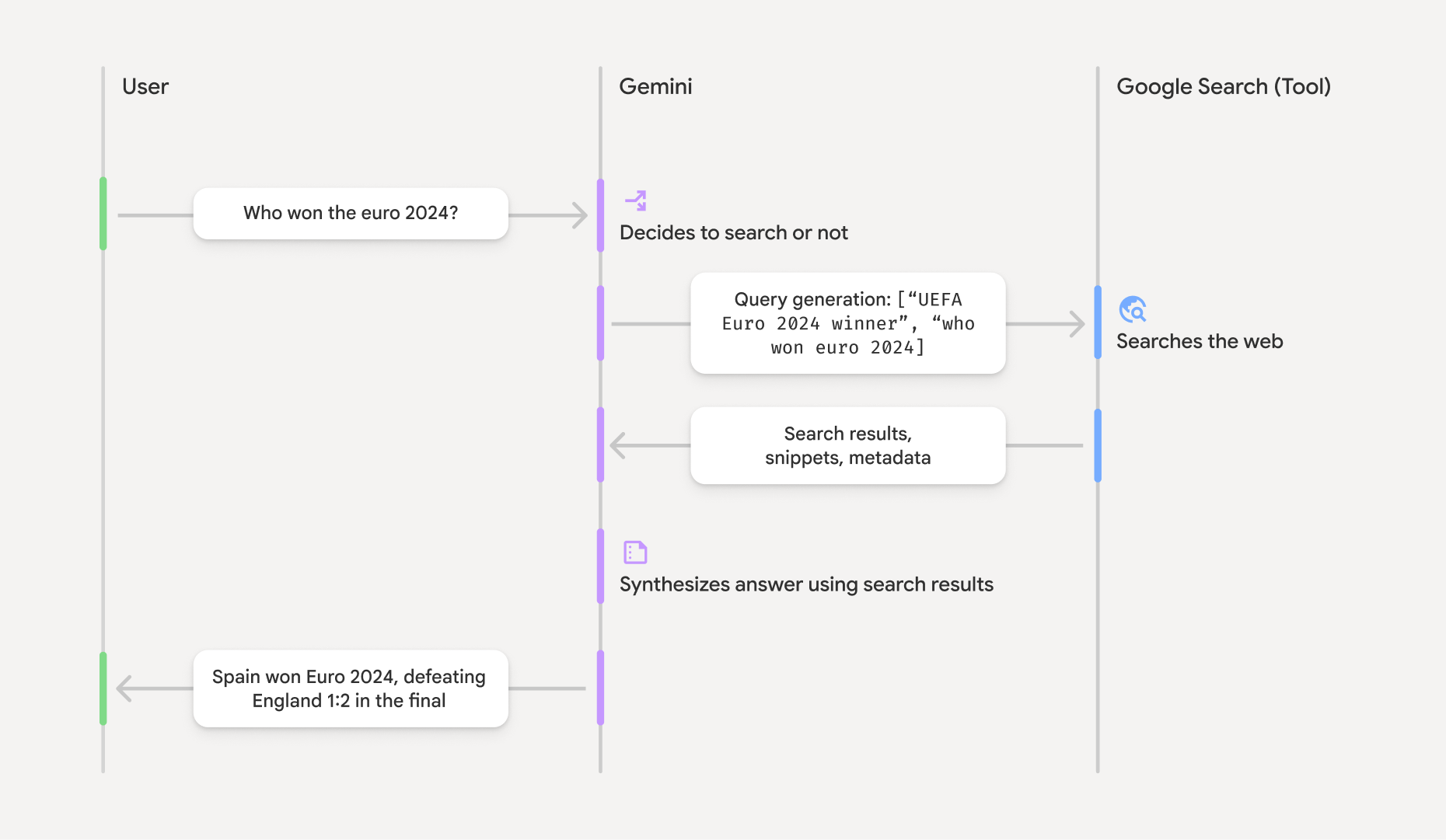
So, how COULD gemini work from prompt to output?
Well before we go into that, keep in mind that Gemini was built from the ground up with native multimodality, it also is integrated with other google products i.e. search for grounding - so the nature of the prompt and prompt media makes a big difference here!
We're going to work on the basis of a text prompt.
So, you've gone to Gemini and you are searching for the cheapest holidays to the USA that are family friendly, the prompt goes in and you ask Gemini.
1. Intent Analysis & Categorization
The very first thing that is likely to happen is an evaluation of the core intent of the prompt. The response structure is routed down different paths depending on what you are asking gemini.
Closed-Form/Technical: If the request is for code fixes, mathematical derivations, translations, or direct logic, the focus is entirely on precision and execution
Exploratory/Strategic: If the request is broad or strategic, the approach shifts to providing high-level structure, practical frameworks, and actionable data
Visual/Experiential: If the request involves physical objects, complex systems, styles, or data comparisons, it triggers a visual evaluation path to determine if diagrams or images are necessary to explain the concept
2. The Verification & Search Loop
Once the intent has been ascertained, the internal knowledge base (pre-existing model training data) is assessed to determine if it is sufficient, or if real-time web retrieval is required, referred to RAG (retrieval augmented generation) - basically, Gemini queries Google Search Index for results.
A live search is triggered if the prompt involves:
Time-sensitive or current events (keeping in mind the current year is 2026).
Highly specific technical documentation, API schemas, or recent industry shifts.
Direct factual claims that require concrete data points rather than generalities.
Data that's outside of the models pre-existing training data
3. The Citation & Grounding Process
The decision of what to cite and how to present it follows a strict verification process, one that we don't fully understand. It isn't a fixed checklist, but rather a set of filtering principles, this is the "vague" part, much like a lot of SEO has been for 20+ years. We understand the concept of what is required but we don't know to which degree the factors are weighted (deterministic), like for YEARS we know Google looked at links, content etc. but the weighting of those things was impossible to gauge, Google never gave us that information, well, Gemini is no different.
Filtering principles (we think)
Concrete Data Over Generalities
Vague statements are actively filtered out, for example, instead of writing "Exercise has many health benefits," the system looks for grounded data, such as "150 minutes of moderate cardio per week reduces cardiovascular risk by 30-40%, according to the American Heart Association." If a specific stat, framework, or regulatory body is responsible for a fact, that source is explicitly named inline.
Handling Personal Context & Sensitive Data
If a prompt touches upon a user's explicit background, preferences, or past interactions, that data is integrated seamlessly without awkward prefaces like "Based on your history."
Furthermore, Gemini has strict guardrails prevent the inference or assumption of any sensitive personal data (such as health conditions, financial records, or political affiliations) unless it is directly and explicitly provided for a specific task. If sensitive data must be used, the exact source is cited to maintain complete transparency- in short, it stops Gemini making assumptions that could create risk if the wrong information were provided.
Strict Terminology Alignment
If external documentation, an image, or a specific technical diagram is referenced, the exact terminology used by that source is adopted. If a source document uses a specific term, that exact phrasing is maintained in the breakdown to avoid confusing translation errors.
4. Structuring for Scannability
The final phase for gemini is formatting the gathered information so it can be digested at a glance, so walls of text are broken down using a specific toolkit:
Procedural Steps: If order is critical to success (like an API integration or a technical setup), a formal step-by-step sequence is used.
Chronological Data: If timelines or dates carry the primary informational weight, the layout organizes them chronologically.
Data Comparisons: If comparing three or more items across multiple attributes, a clean Markdown table is used to prevent messy text lists.
Key Nuances: Critical warnings, underlying mechanics, or "gotchas" are highlighted in blockquotes to separate them from the main narrative.
In short, it is a varied, adaptive process designed to give a direct, grounded answer first, back it up with concrete facts or sources where necessary, and present it in the cleanest layout possible.
Now, what is KEY here is that we've talked about Gemini's process, but, ultimately the SELECTION phase for citations is where it's impossible to really understand how Gemini is selecting, it's VERY probable that Gemini is going to have a wide selection criteria that changes depending on the nature of the prompt, intent, risk classification i.e. YMYL.
Some things we are fairly sure are going to make a difference:
Having a stronger organic presence in Google Search is likely to increase selection criteria because Google's algo's for ranking have almost filtered out the sites that deserve to rank (quality of content, helpfulness, trust etc)
Content quality (this is broad but would cover things such as intent alignment, factual correctness, tone of voice, writing perspective, freshness, external fact validation, NLP)
Authority - so, Google's pagerank algo forms a part of Google's core search algo grouping, so potentially this could be factored in - in respect of authority and trust
Anyhow - the rabbit hole could get really deep here - SO, on to the next part, what kind of things do we typically do (as part of general SEO and to help improve visibility in AI Overviews - and indirectly Gemini?)
We start by getting the foundations in place
The most common mistake we see is treating "Gemini" as one thing. The reality is, it isn't, there are two distinct parts to it, each with its own access control - typically:
AI Overviews and AI Mode rely on Google Search and are governed by standard Googlebot access. You cannot opt out of them without leaving Google Search entirely, and you wouldn't want to - businesses have nothing to gain by trying to "opt out" of AI (I bring this up because of people considering blocking bots via cloudflare - almost as like a protest)
The Gemini app and the Gemini/Vertex API's grounded answers are governed by the Google-Extended directive. So, ensuring open access is the most basic thing here, not placing any restrictions anywhere that could ultimately lead to a loss of visibility
Google-Extended is a directive, not a crawler so it never appears in server logs, and we sometimes find it silently re-enabled or disabled - so this is a key thing to check for
Many sites blocked Google-Extended during the AI opt-out wave of 2024/2025 and are now invisible to Gemini grounding without realising it doh!
We treat GOOD GEO/AI SEO as SEO
Because Gemini grounds on Google's index, AI citation eligibility is overwhelmingly a function of organic strength - the better your rankings in Google the higher the probability you have of being cited in Gemini's responses.
We don't adopt "AI tactics" or any of these BS AI visibility hacks on pages with a ranking problem, we fix the ranking problem first, and the AI visibility tends to follow. I have to make this ABUNDANTLY clear - if your website has a poor SEO profile you shouldn't be focusing on AI search at all, you should be focused on getting your SEO fundamentals right and ONLY THEN should you even think about appearing in LLMS like Gemini (or chatGPT, Claude, Perplexity, Grok etc).
Remember - as Google moves the goalpost with algo refinements & a seemingly more aggressive stance on indexing - falling short with ranking losses and indexing issues is going to only increase the challenges you face in getting cited in Gemini, I've seen SO many businesses chasing the AI hype train, focusing on links, GEO & desperately chasing AI visibility when their organic performance would simply not allow for it.
Google is DEINDEXING millions of pages daily, why? because of programmatic slop, AI content & the fact that index, storage & processing costs $$$$$$ - so, if your site is a victim of losses, focus on that before anything else.
So, onwards with more of what we do >
We clean up a websites technical SEO, we maximise technical seo compliance
We perform all the required render checks to eliminate issues with CSR / SSR / Javascript / Dynamic content
We clean up failing search indexes - we identify what google is not indexing and why, we clean this up so that a website can have a tight & clean indexing profile
We perform content audits and content cleanups
We audit content for NLP, topical coverage, sentiment, SEU, readability, tone of voice, writing perspective, content prioritisation, intent alignment, engagement (user behaviour), query counts & internal links
We audit the domains link profile assessing (link accruement rate, domains with traffic, referring domain distribution, link context, topical trust flow, citation flow, anchors)
We audit the brand profile (brand search volume, search trends, search variations, brand sentiment, brand UGC mentions, reviews & other external factors)
We make sure target pages rank in the top ten for the realistic sub-questions a user actually asks, not just the head term - we get PAA data from alsoasked.com
We build genuine, machine-legible E-E-A-T: named authors with real credentials, first-hand experience, and proprietary data not thin aggregated rewrites.
We prioritise original insight, because restating what every other page says is precisely what now gets de-prioritised, and what AI engines have no reason to cite - in short, we use writers to edit and update content so that it adds unique added value
Of course the above is over-simplifying it, but we basically ensure the website has a solid technical SEO profile, solid indexing profile, solid content profile and solid link profile - some we address in one swoop i.e. technical SEO whiilst other things are "ongoing" tasks such as content writing for experiments, link building etc.
TECHNICAL SEO COMPLIANCE IS CRUCIAL!
To help those who are still learning I made a 2 part technical SEO webinar series which is around 12 hours of SEO training to take SEOS to a pro level in technical SEO.
Preview here >
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1066144387?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="Technical SEO Webinar - Levelling Up - Course Sample"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>You can get the webinar series here >
https://seo-audits.io/technical-seo-levelling-up-webinar/

For Content we optimise the passage, not just the page
This is the part that genuinely separates Gemini-era SEO from the traditional SEO processes. AI Mode and Gemini's grounding break a single query into many sub-queries, a process known as query fan-out & then runs them concurrently to assemble the answer from self-contained passages pulled from across the web.
Another highly intelligent & fantastic SEO (Dan Petrovic) has built a query fan out tool which you can use here: https://dejan.ai/tools/fanout/
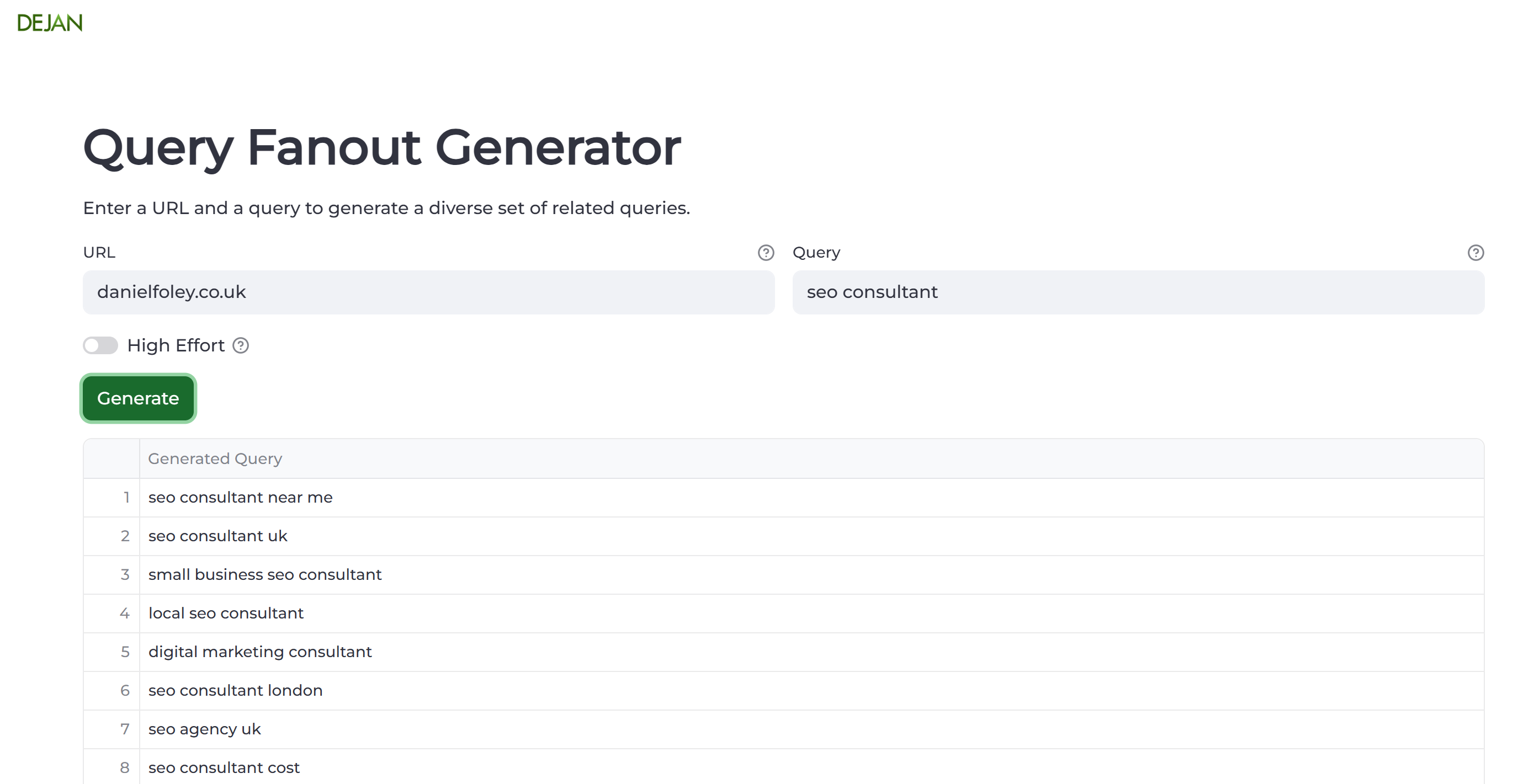
This allows you to see the sub-set of queries that could be used in fan out by providing a source query.
Another SEO legend (Mark Williams-Cook) has made QueryFan.com - check it out (although you'll need to get in early before the community uses run out)
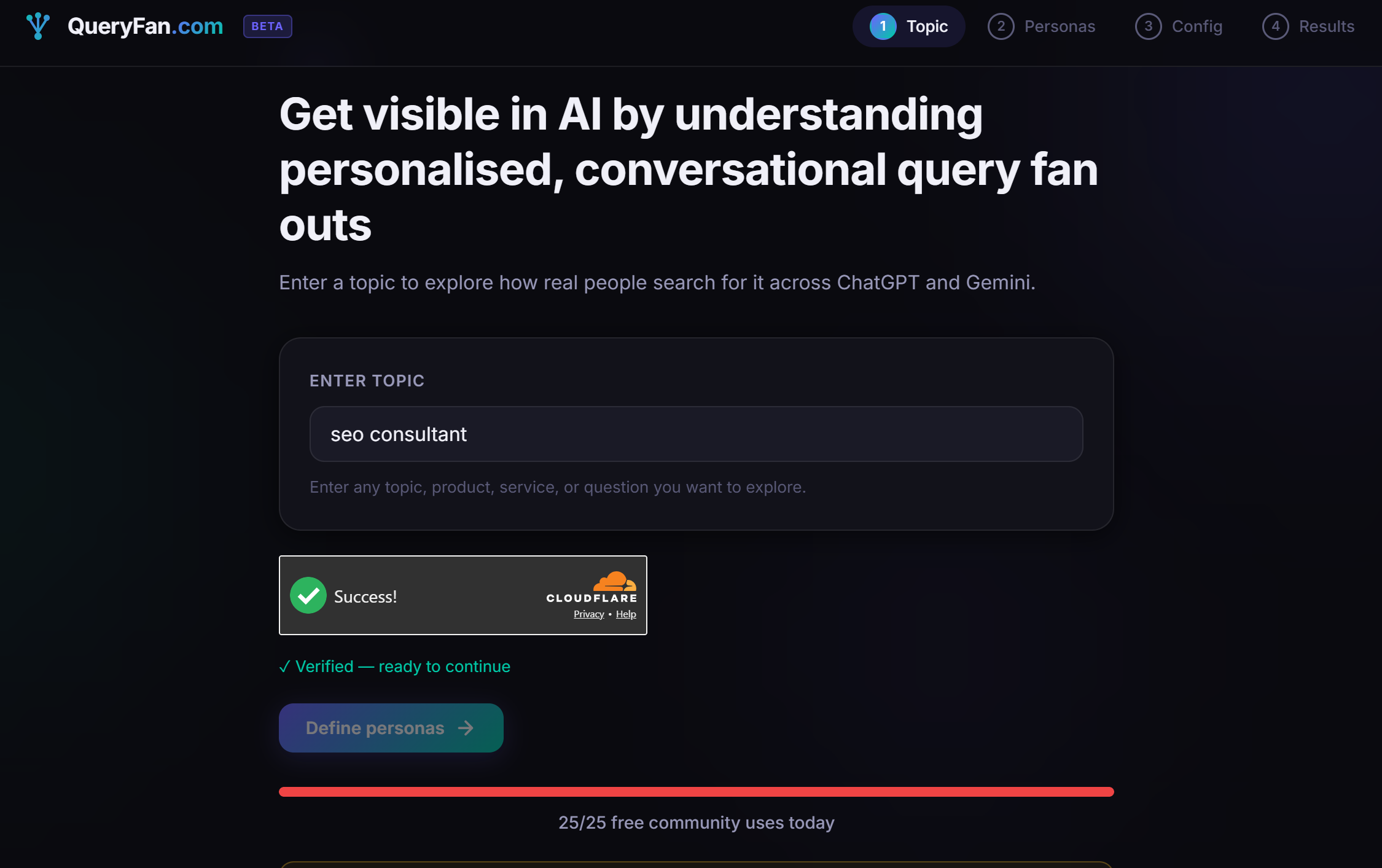
Anyhow, I am diverging here - query fan out is the subset of searches performed by LLMS including Google Gemini.
The part of the content that gets cited is the passage, not the page. We structure content so that the most valuable blocks can stand alone and be lifted directly into an answer.
Every section answers one discrete question and makes sense on its own, without the surrounding paragraphs.
We lead with the answer and follow with the supporting detail, so the citable claim sits at the top of the block.
We map and explicitly cover the fan-out questions a user branches into definitions, comparisons, costs, "is it worth it", "how does it work" - rather than hoping one page covers them by accident.
We write with high information density: specific figures, named entities, dates and concrete steps, in the formats AI engines extract most readily, including tables and comparison blocks.
We make sure the facts that matter are in text, never trapped in an image, a PDF, or an interactive widget the model can't read.
We extract data via PAAs and query fan out data - alsoasked.com is a good source for PAA data.
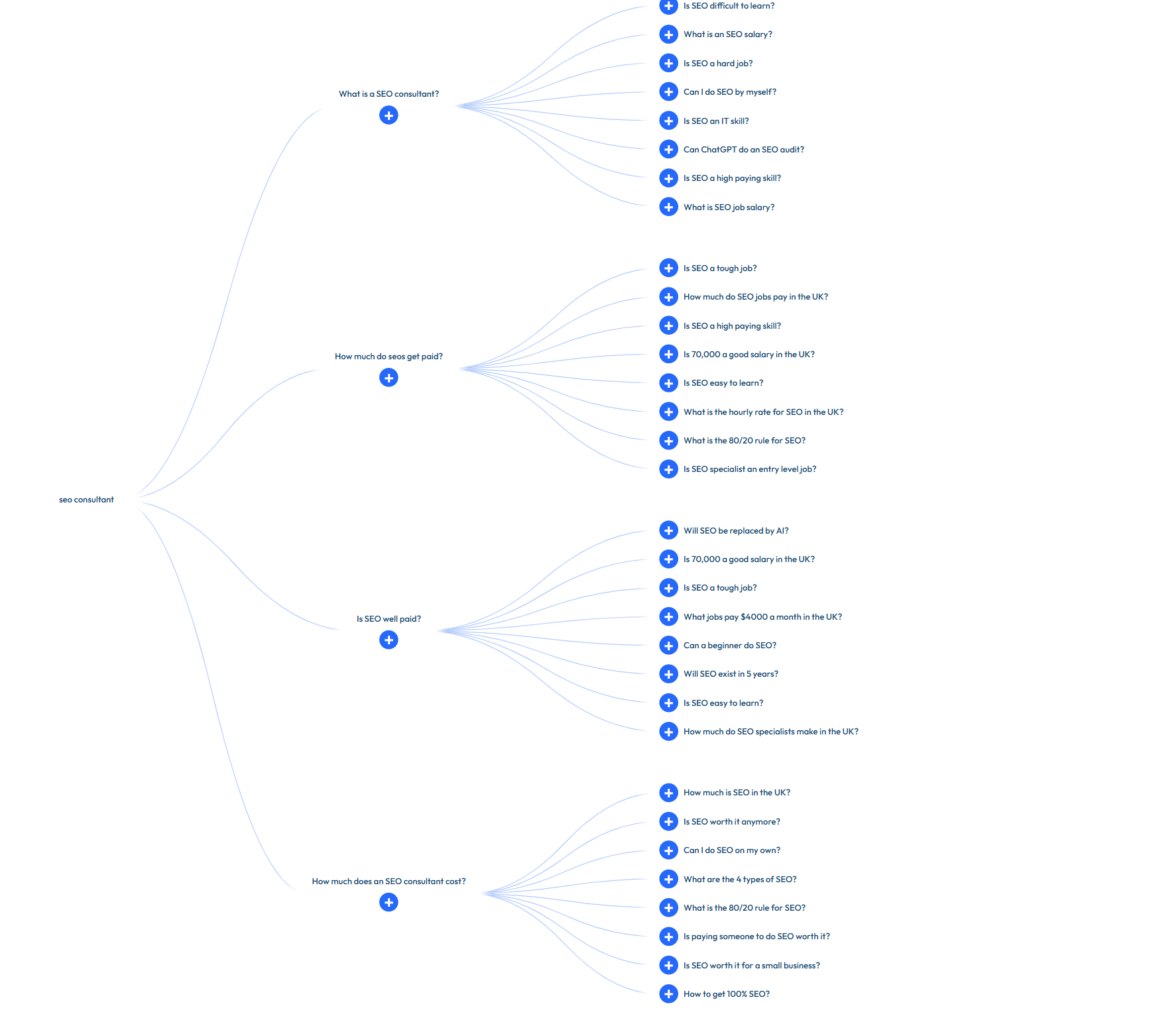
We also extract data from SEO Stack as this basically gives us ALL Google search console data which we can use:
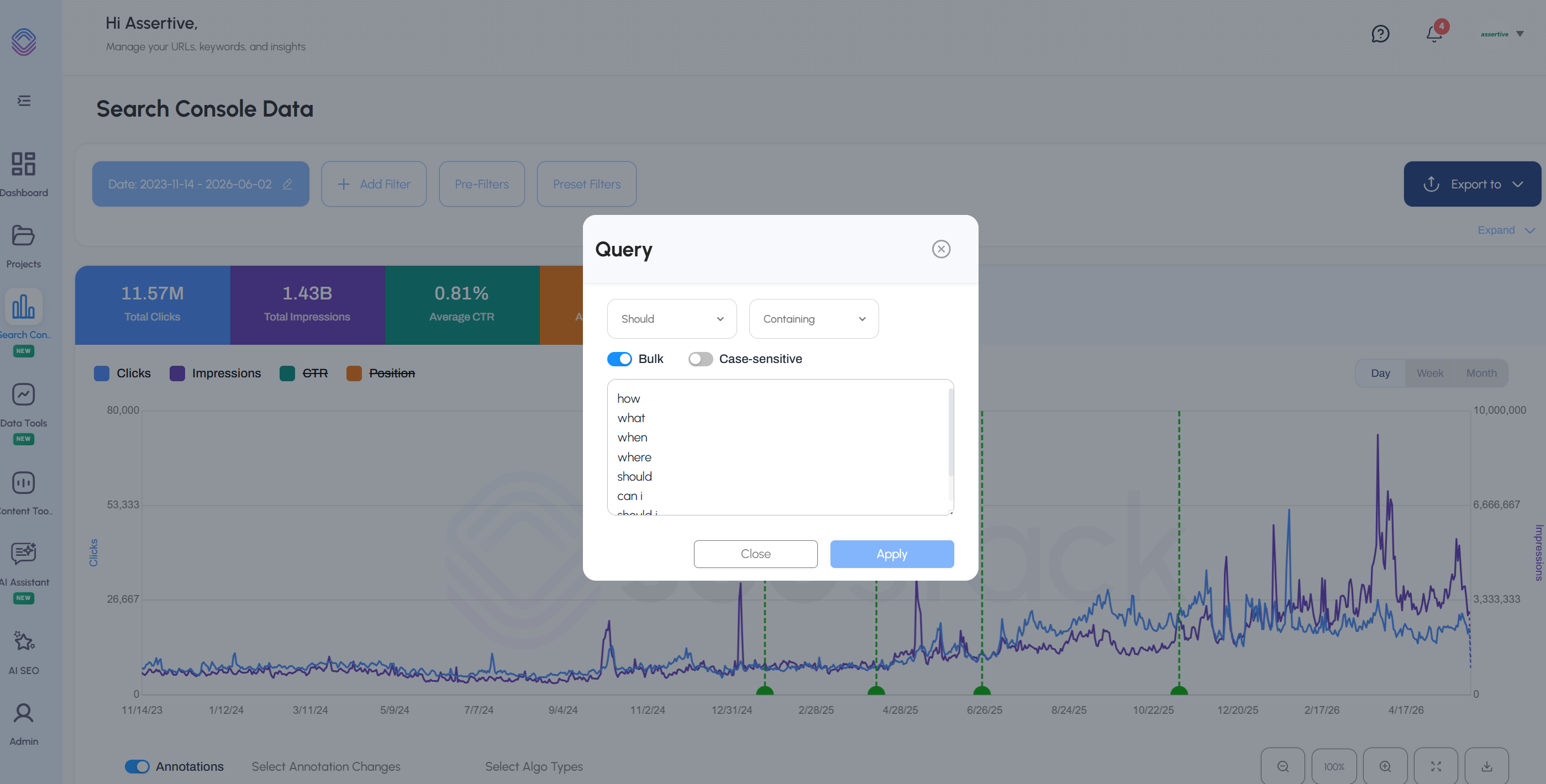
We use SEO Stacks powerful filtering system to extract all the relevant questions from the GSC data -
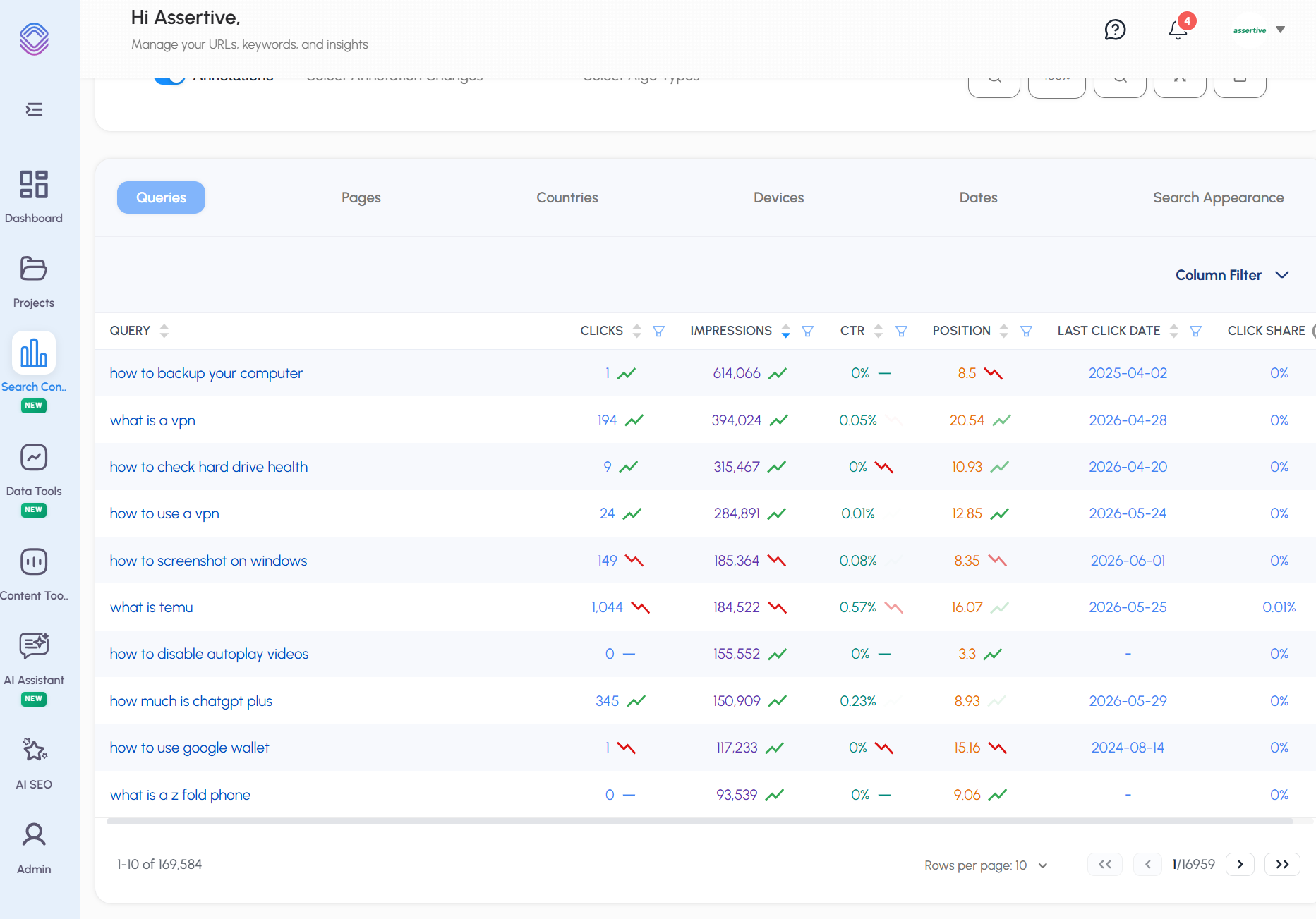
Combining Query Fan Out data with AlsoAsked PAA & SEO Stack GSC data allows us to get a really good view of what people are searching for, question sub-sets and what kinds of things we should be answering within content.
We build entity signals Gemini uses
Gemini leans on Google's Knowledge Graph heavily. That makes entity clarity Google understanding exactly who you are, what you do, and what you should be associated with disproportionately valuable for Gemini specifically.
Google doesn't require structured data for its AI features, but used well it removes ambiguity, and ambiguity is what causes an AI to describe you incorrectly or attribute your expertise to someone else.
Here is where tools such as WAIKAY come in - (What AI Knows About You)
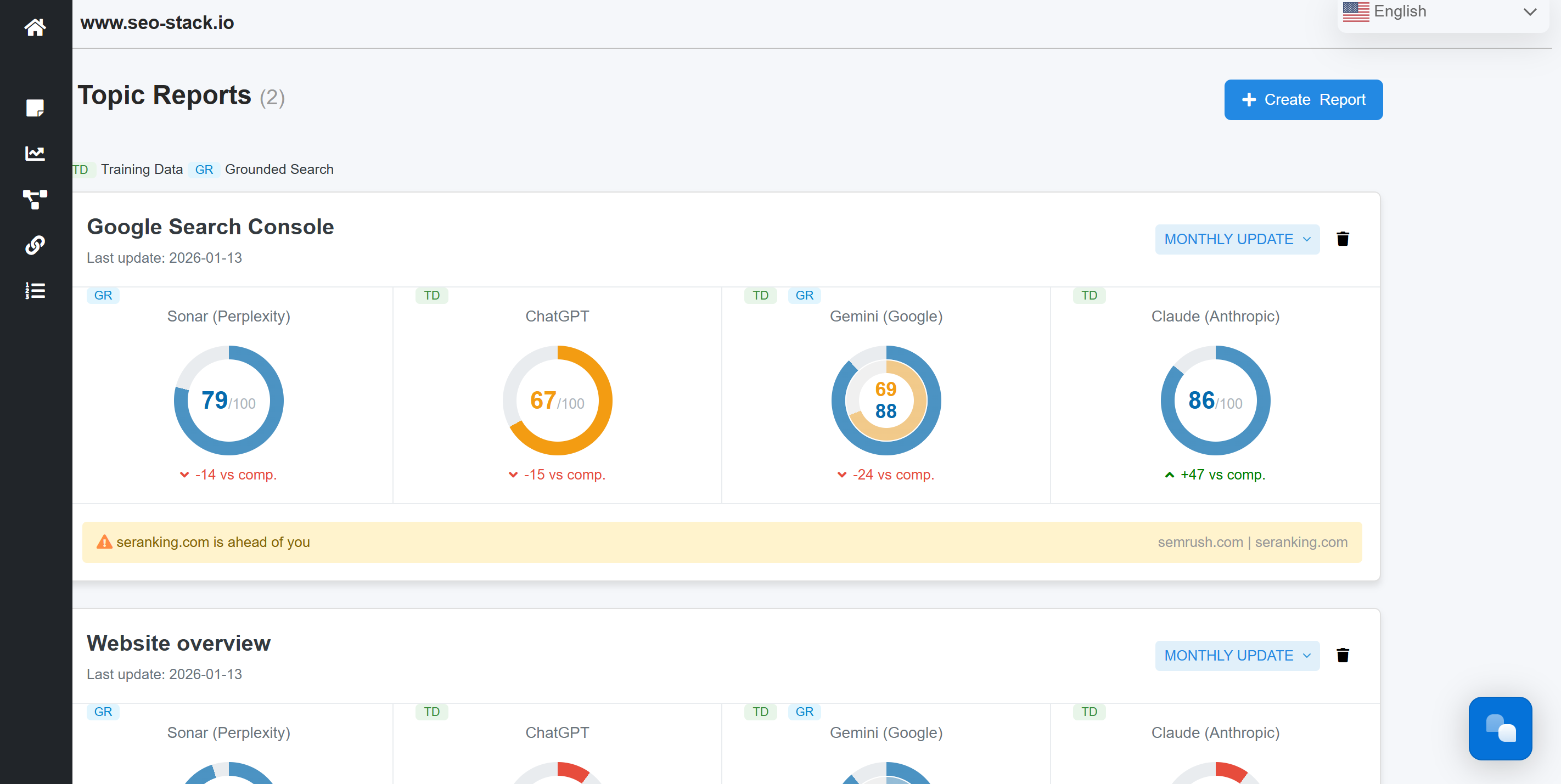
It's important that you understand what AI's like Gemini already understand about your brand.
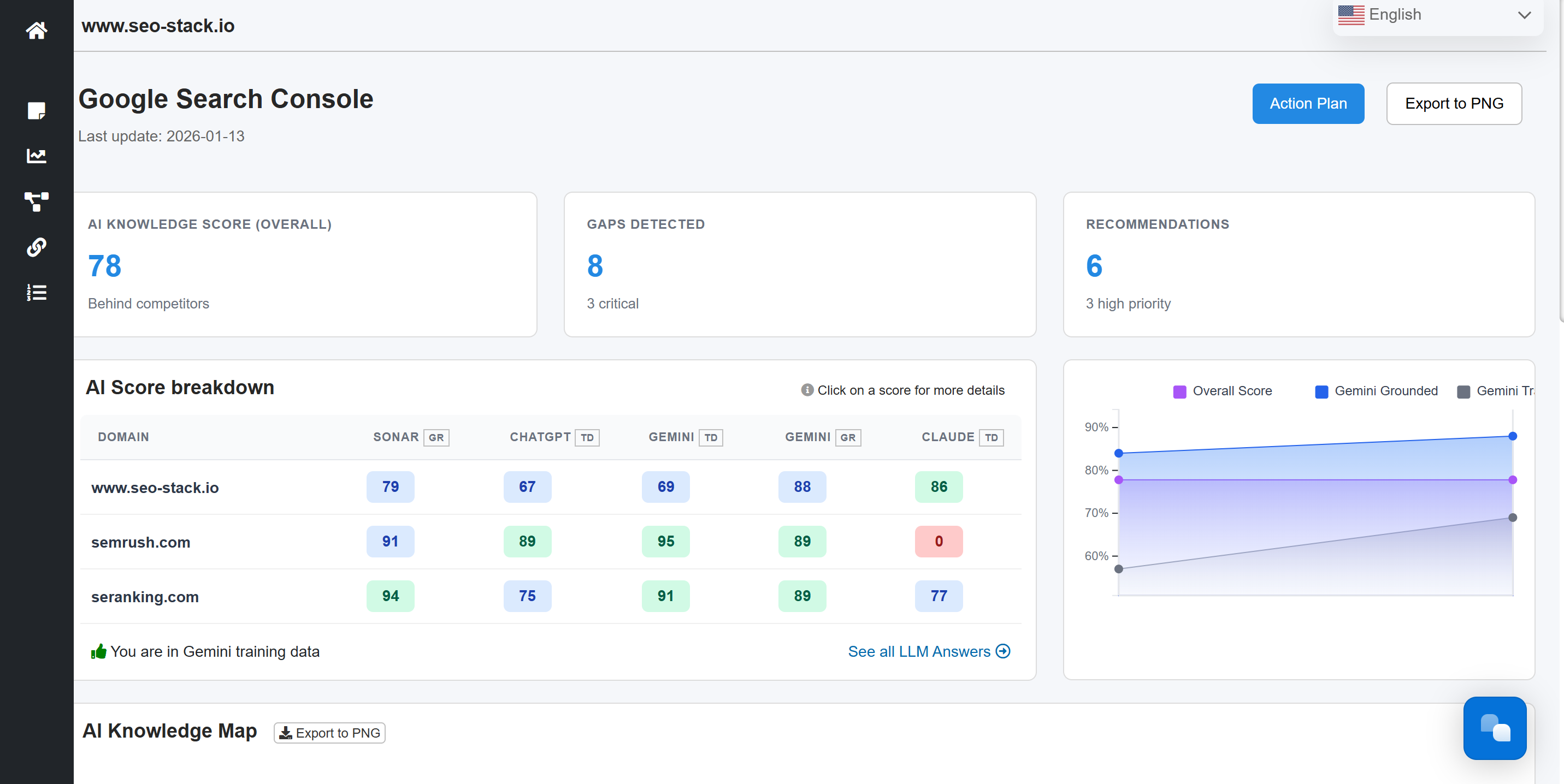
With WAIKAY it's easier to understand what AI knows about your brand, product, offering - pls you can get insights, recommendations, content gaps etc.
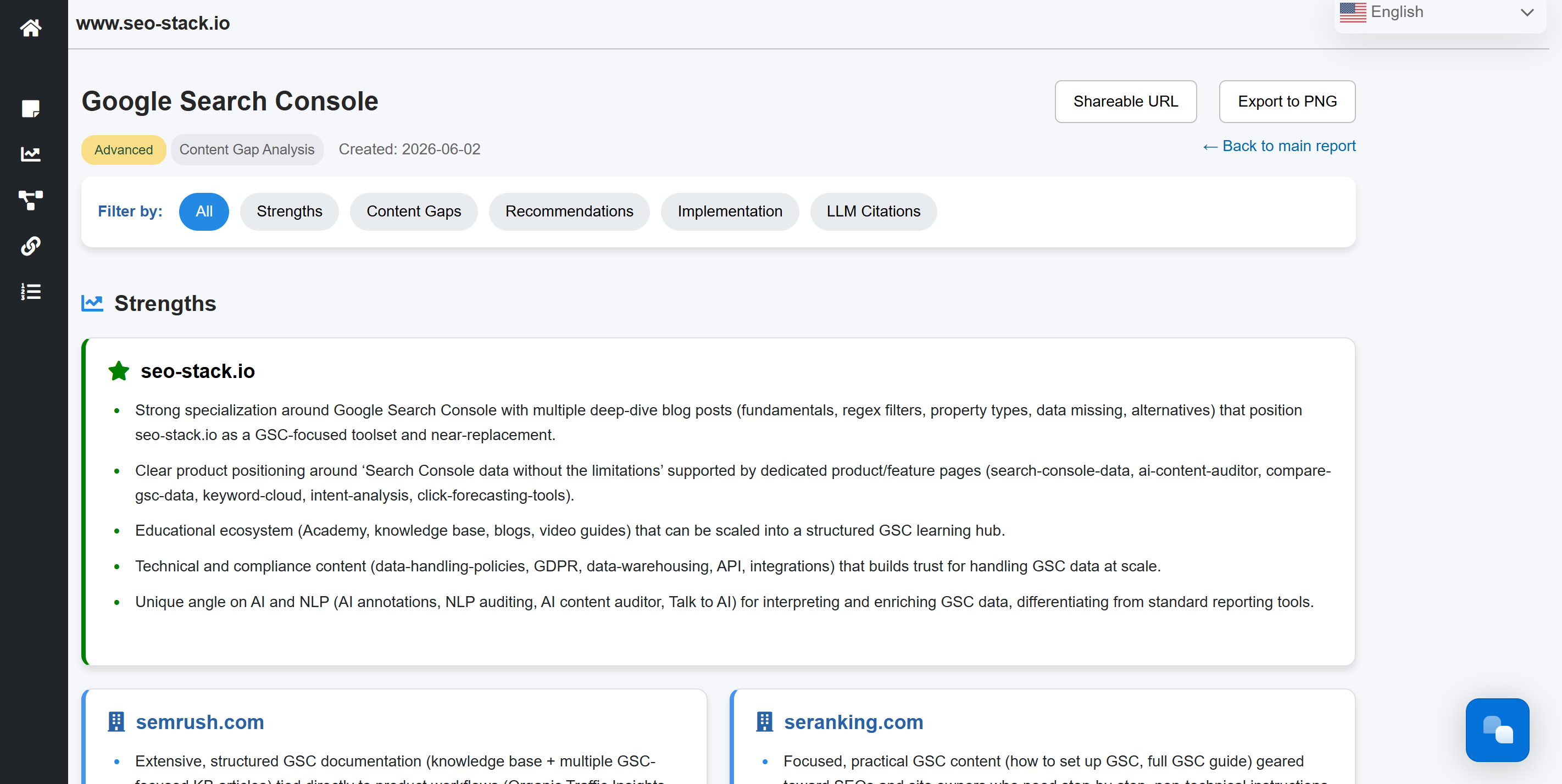
This forms part of optimising for Gemini and indeed other LLMS (chatGPT, claude etc).
Some of the things we do include:
We implement clean Organization and, for software clients, SoftwareApplication structured data, we determine the structured data profile for each client, with sameAs links to verified profiles that anchor your identity.
We enforce entity consistency across the web, so your name, category and core claims are described the same way on your own pages, your profiles, and third-party sources.
For local businesses, we align LocalBusiness schema with the Google Business Profile so location-specific answers are accurate.
We work on third-party consensus, because Gemini's confidence in recommending you grows when trusted independent sources already describe and endorse you not just your own domain.
Again - this is oversimplifying it, we do more - but fundamentally we adopt structured data and we focus on consistency and ensuring that AI knows the right things about your brand/offering.
We keep content fresh, deliberately
Google weights temporal signals when deciding which sources to trust for anything time-sensitive. We use that properly through genuine updates that earn a re-crawl rather than the date-spoofing shortcuts that now do more harm than good - lots of people tried to play with lastmod thinking Google would work on that alone (when it can easily compare an indexed snapshot to a current version - dur!)
We update dateModified only when there is substantive new content behind it, and either trigger a re-crawl or just leave it if Google is indexing content / discovering or refreshing at a healthy rate
We run a deliberate refresh cadence on pages targeting "best", "latest" and year-stamped queries, where freshness is a ranking and citation factor rather than a nicety
We measure what can actually be measured
We are honest with clients about the limits here, because overclaiming is its own form of amateurism. Google folds AI Overview and AI Mode performance into total Search performance, so nobody can cleanly isolate "AI traffic" from Search Console alone. For Gemini we can report via GA4 data studio reports.
We segment referral data to approximate sessions arriving from Gemini's own referral source.
We track citation share how often, and how accurately, your brand is actually named in AI answers as a metric distinct from rankings.
We monitor how the AI describes you, because a brand being mis-described is a fixable entity-signal problem, not a ranking one and catching it early protects how millions of AI answers represent you.
Again - over simplification here - we do a lot more but the CORE of what we do is covered above.
To help others - I have put together a usable checklist you can add to your SEO strategies with clients who are interested in pushing harder on AI visibility.
One thing I will add to this that I feel is important and that's AI search still only has a tiny footprint when compared to traditional search.

Client Checklist for Google AI Products
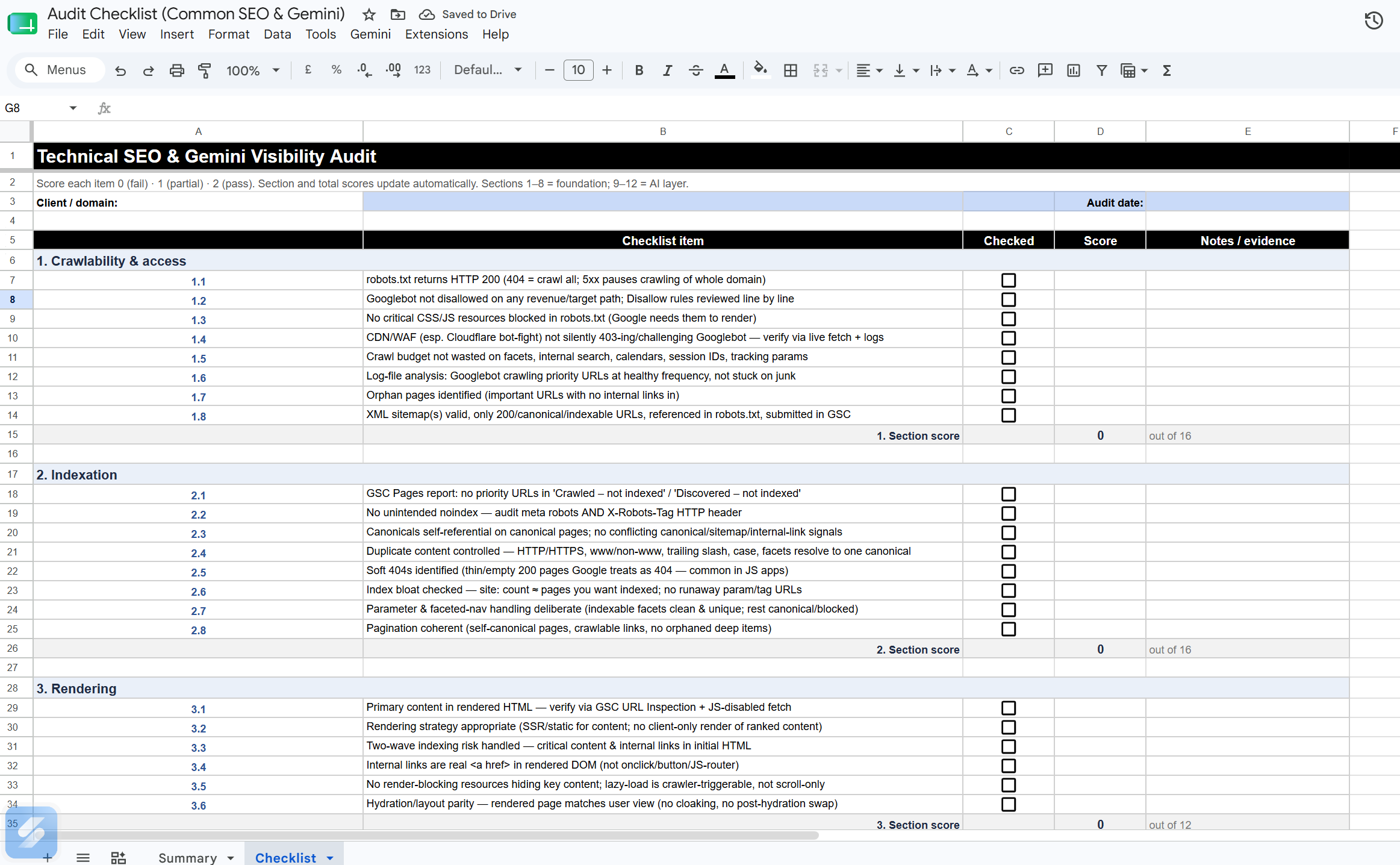
Section 1 - Crawlability & access (16 pts)
Can search engines and AI fetchers reach the content at all? Without this, nothing else works or matters.
1.1
robots.txtreturns HTTP 200 (a 404 = "no restrictions, crawl everything"; a 5xx makes Googlebot pause crawling the whole domain).___/21.2 Googlebot is not disallowed on any revenue/target path;
Disallowrules reviewed line by line for over-broad patterns.___/21.3 No critical CSS/JS resources blocked in
robots.txt- Google needs them to render the page (see Section 3).___/21.4 CDN/WAF (especially Cloudflare bot-fight / managed challenge) is not silently 403-ing or challenging Googlebot. Verify with a live fetch + server logs, not assumptions.
___/21.5 Crawl budget is not wasted on low-value URLs - faceted navigation, internal search results, infinite calendars, session IDs, and tracking parameters are controlled (robots, canonical, or parameter handling).
___/21.6 Log-file analysis done (or sampled): confirm Googlebot is actually crawling priority URLs at a healthy frequency and not stuck on junk.
___/21.7 Orphan pages identified - important URLs with no internal links in are effectively invisible to crawl discovery.
___/21.8 XML sitemap(s) present, valid, free of non-200/non-canonical/noindexed URLs, referenced in
robots.txt, and submitted in GSC.___/2
Section 2 - Indexation (16 pts)
Of what's crawled, what actually makes it into the index - and is it the right version? what should and should not be indexed? what are the main non indexed reasons?
2.1 GSC Index Coverage / Pages report reviewed: no priority URLs stuck in
Crawled – currently not indexedorDiscovered – currently not indexed(the classic quality/crawl-priority signals).___/22.2 No unintended
noindex- audit meta robots andX-Robots-TagHTTP headers; a staging-leaknoindexin a header is invisible in page source.___/22.3 Canonical tags are self-referential on canonical pages and point to the correct target on variants; no conflicting signals (canonical says A, sitemap lists B, internal links point to C).
___/22.4 Duplicate / near-duplicate content controlled - pagination, faceted URLs, HTTP/HTTPS, www/non-www, trailing-slash, and uppercase/lowercase variants resolve to one canonical.
___/22.5 Soft 404s identified - thin/empty pages returning 200 that Google treats as 404s (common on filtered category pages and JS apps that render an empty shell).
___/22.6 Index bloat checked -
site:count roughly matches the count of pages you actually want indexed; no runaway parameter or tag-archive URLs.___/22.7 Parameter & faceted-nav handling deliberate: indexable facets have clean static-style URLs and unique value; the rest are canonicalised or blocked.
___/22.8 Pagination handled coherently (self-canonical paginated pages with crawlable
rellinks, or a sound load-more/view-all alternative) — no orphaning of deep items.___/2
Section 3 - Rendering (12 pts)
What does Google actually see after rendering? This is where JS-heavy stacks tend to fail or create compounding indexing and rendering issues.
3.1 Primary content is in the rendered HTML - test with GSC URL Inspection (live test > rendered HTML + screenshot) and a JS-disabled fetch. Content that only appears after a user event is not reliably indexed.
___/23.2 Rendering strategy is appropriate: SSR or static generation for content pages; if CSR, dynamic rendering or hydration that doesn't strip content. Avoid client-only rendering of anything you need ranked.
___/23.3 Two-wave indexing risk accounted for - Google renders JS on a deferred queue, so heavy client-side dependency delays indexing of content and links. Critical content and internal links should be in the initial HTML.
___/23.4 Internal links are real
<a href>elements in the rendered DOM - notonclickhandlers, buttons, or JS-router links that Google can't follow as links.___/23.5 No render-blocking resources preventing key content/layout from rendering for the crawler; lazy-loaded content uses native lazy-loading or intersection observers Google can trigger, not scroll-only loading.
___/23.6 Hydration / layout parity - the rendered page Googlebot sees matches what users see (no cloaking, no content swapped in after hydration that differs from the SSR payload).
___/2
Section 4 - Site architecture & internal linking (10 pts)
4.1 Crawl depth - priority pages reachable within ~3 clicks of the homepage; nothing important buried.
___/24.2 Logical hierarchy - clear hub/category > subcategory > detail structure that matches how topics relate.
___/24.3 Internal linking distributes equity to priority pages; high-authority pages link down to the targets that need to rank.
___/24.4 Descriptive anchor text on internal links (not "click here") - it's a relevance signal for both ranking and entity understanding.
___/24.5 Breadcrumbs implemented with
BreadcrumbListschema, reinforcing hierarchy and surfacing context.___/2
Section 5 - On-page & content (12 pts)
5.1 Title tags unique, descriptive, intent-matched, front-loaded; no templated duplication across the site.
___/25.2 Meta descriptions present and compelling (don't affect ranking directly, but drive CTR and are often the snippet source).
___/25.3 Heading hierarchy logical and unique - one clear
H1, properly nestedH2/H3, each describing the block beneath it.___/25.4 Search intent match - page type fits the query (informational vs transactional vs navigational); no mismatch between what ranks and what the user wants.
___/25.5 E-E-A-T signals - named authors with credentials, first-hand experience, proprietary data; reinforced by the May-2026 Core Update's emphasis on demonstrable expertise and original insight over volume.
___/25.6 Content depth & originality - covers the topic and its sub-questions thoroughly with a genuine perspective, not a thin rewrite of the consensus.
___/2
Section 6 - Technical health (14 pts)
6.1 HTTPS sitewide, valid certificate, no mixed-content warnings; HTTP>HTTPS enforced via 301.
___/26.2 Status codes correct - live pages 200, removed pages 410/404 (not soft-200), moved pages 301.
___/26.3 No redirect chains or loops - each redirect is a single 301 hop to the final target; internal links point to the final URL, not through a redirect.
___/26.4 Single canonical host & protocol - one of www/non-www and https enforced; no duplicate accessible versions.
___/26.5 Broken links (internal 404s and broken outbound links) found and fixed.
___/26.6 hreflang (international/multi-language sites) - correct language-region codes, return tags reciprocal,
x-defaultset, and consistent with canonicals.___/26.7 Custom 404 that returns a true 404 status and routes users helpfully; no large-scale soft-404 patterns.
___/2
Section 7 - Performance & Core Web Vitals (8 pts)
7.1 LCP within threshold on mobile (the field-data view in GSC / CrUX, not just lab).
___/27.2 INP within threshold (the responsiveness metric that replaced FID).
___/27.3 CLS within threshold - no layout shift from late-loading images/ads/fonts (set dimensions, reserve space).
___/27.4 Render path optimised - critical CSS prioritised, JS deferred/code-split, images compressed and correctly sized/next-gen format, caching and CDN in place.
___/2
Section 8 - Mobile (6 pts)
8.1 Mobile-first indexing parity - the mobile page contains the same primary content, structured data, and internal links as desktop (Google indexes the mobile version).
___/28.2 Responsive, usable - legible without zoom, tap targets adequately sized, no horizontal scroll, no intrusive interstitials.
___/28.3 No mobile-only blocking - resources, content, or links aren't hidden/blocked specifically on mobile.
___/2
Section 9 - AI & access control (8 pts)
The Gemini-specific access layer. Two distinct parts with different controls - conflating them is the most common client error.
9.1
Google-Extendeddecision is deliberate and documented - allowed if the client wants Gemini-app/API grounding visibility; if blocked, confirm it was an intentional training opt-out, not a CMS default or a leftover from the 2024 opt-out wave.___/29.2
Google-Extendedis a directive, not a crawler - it never appears in server logs and is silently overwritten by some CMS updates. Audit the live file, not your memory of it.___/29.3 No
nosnippet/max-snippet:0/data-nosnippeton body content you want served in AI Overviews (these suppress AI extraction as well as snippets).___/29.4 Client understands they cannot cleanly opt out of AI Overviews/AI Mode while staying in Search - expectations set before any robots change.
___/2
Section 10 - Passage extractability (12 pts)
AI Mode and Gemini grounding decompose a query into many sub-queries ("query fan-out"), run them concurrently, and assemble the answer from self-contained passages. The content that gets cited is the passage, not the page.
10.1 Each
H2/H3block answers one discrete question and stands alone without the surrounding context.___/210.2 Direct-answer-first structure - the claim/answer leads the block; supporting detail follows.
___/210.3 Sub-query coverage - the page explicitly addresses the fan-out questions a user branches into (definitions, comparisons, "vs", "how", "cost", "is X worth it"). Map these before scoring.
___/210.4 Information density - specific figures, named entities, dates, concrete steps per passage; no padding.
___/210.5 Lists, tables, and comparison blocks used where the query implies enumeration/comparison (highly extractable formats).
___/210.6 Key facts are in text, not trapped in images, PDFs, or interactive widgets with no text equivalent.
___/2
Quick leading indicator: grade the 5 highest-intent passages on 10.1–10.2 only (0/1/2 each, /20) and track the average over time. It moves before citations do.
Section 11 - Entity & Knowledge Graph signals (10 pts)
Gemini leans on Google's entity graph far more than Bing-based engines do. Google doesn't strictly require schema for AI features, but it removes the ambiguity that causes an AI to describe you incorrectly.
11.1
OrganizationJSON-LD withsameAsto verified profiles (LinkedIn, Wikidata/Wikipedia if present, Crunchbase, etc.).___/211.2 Relevant type-specific schema valid and shipped (
SoftwareApplication,Product,Article,FAQPage,LocalBusinessas applicable).___/211.3 Entity consistency across the web - name, category, and core claims described the same way on owned pages, profiles, and third-party sources.
___/211.4 Local clients:
LocalBusinessschema aligned with Google Business Profile (NAP parity).___/211.5 Third-party consensus - the brand is described/recommended on sources Gemini already trusts (industry roundups, reviews, reputable directories), not only owned domains.
___/2
Section 12 - Freshness, authority & measurement
Freshness (6 pts)
12.1
dateModifiedreflects genuine updates (date-spoofing without substantive change is a liability).___/212.2 Sitemap
lastmodaccurate; meaningful updates resubmitted to prompt re-crawl.___/212.3 Refresh cadence exists for "best / latest / 2026"-type queries where freshness is a citation factor.
___/2
Authority (4 pts)
12.4 Backlink profile - quality/relevance of referring domains reviewed; toxic/spam links assessed; no unnatural patterns.
___/212.5 Digital PR / link velocity healthy and earned, supporting both ranking and the third-party consensus AI engines rely on.
___/2
Measurement (no points - instrument before claiming wins)
12.6 Accept that GSC folds AI Overview + AI Mode into total Search performance - don't promise clients a clean "AI traffic" line from GSC alone.
12.7 Segment GA4 referrals from
gemini.google.comand grounded-answer referrers to approximate Gemini-app-sourced sessions.12.8 Track citation share (brand named in AI answers) with a dedicated monitor, separate from rank tracking.
12.9 Track how the AI describes the brand - mis-description is a fixable entity-signal problem (Section 11), not a ranking one.
I've put the above into a Google Sheet as a checklist that you can make a copy of and use at your own discretion.
Access it here >
To make a copy simply click FILE > MAKE A COPY
Then use this at your own discretion.